Full Text Search by Pure JavaScript
There are several ways to add a full text search for a website:
- Using in-site search, such as using Google to search
xyz site:example.com. The disadvantage is that it is not real-time; - Using Elastic Search, which needs a dedicated server, and usually 3 nodes if using cloud service, very expensive;
- Using Redisearch, which needs a Redis server with plugin, and additional development work.
For small and medium-sized web sites, the number of pages that need to be indexed is not large, it is possible to use a pure JavaScript based search engine to build the index, and provides real-time search.
GitSite uses FlexSearch, a search engine written in JavaScript, to implement real-time search:
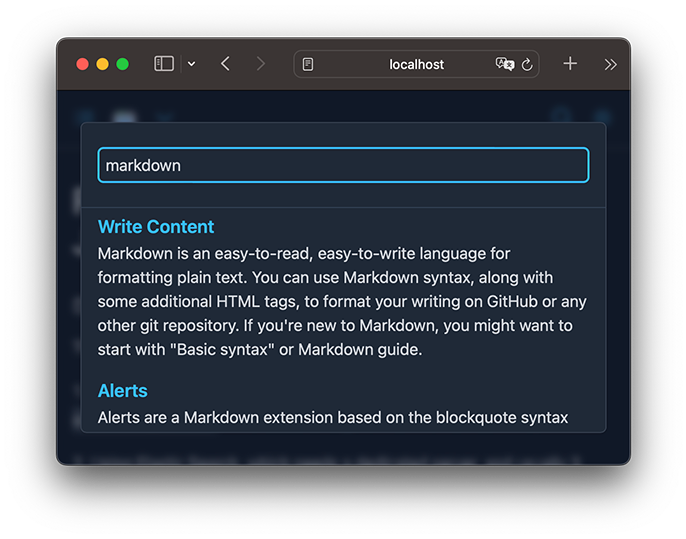
Use FlexSearch is relatively simple, but the default tokenizer does not support Chinese. The official document gives a simple algorithm to split words for CJK:
var index = FlexSearch.create({
encode: str => str.replace(/[\x00-\x7F]/g, "").split("")
});
It works, but English becomes unavailable, because it only recognizes the CJK characters and drops all other words including English.
So we need to write a more comprehensive algorithm to support both English and Chinese.
In JavaScript, every character has a Unicode encoding. Here is a good Unicode encoding reference. [1]
We can divide characters into two major categories:
One is English, French, German and other letters, which rely on spaces to separate words. We list the Unicode encoding range and use isAlphabet() to identify:
const ALPHABETS = [
[0x30, 0x39], // 0-9
[0x41, 0x5a], // A-Z
[0x61, 0x7a], // a-z
[0xc0, 0x2af], // part of Latin-1 supplement / Latin extended A/B / IPA
[0x370, 0x52f], // Greek / Cyrillic / Cyrillic supplement
];
function isAlphabet(n) {
for (let range of ALPHABETS) {
if (n >= range[0] && n <= range[1]) {
return true;
}
}
return false;
}
One is Chinese, Japanese and other texts, where one character is one word. We also list the encoding range of Unicode and use isSingleChar() to identify:
const SINGLE_CHARS = [
[0xe00, 0x0e5b], // Thai
[0x3040, 0x309f], // Hiragana
[0x4e00, 0x9fff], // CJK
[0xac00, 0xd7af], // Hangul syllables
];
function isSingleChar(n) {
for (let range of SINGLE_CHARS) {
if (n >= range[0] && n <= range[1]) {
return true;
}
}
return false;
}
Now we can implement a function for word segmentation:
function tokenizer(str) {
const length = str.length;
const tokens = [];
let last = '';
for (let i = 0; i < length; i++) {
let code = str.charCodeAt(i);
if (isSingleChar(code)) {
if (last) {
if (last.length > 1) {
tokens.push(last.toLowerCase());
}
last = '';
}
tokens.push(str[i]);
} else if (isAlphabet(code)) {
last = last + str[i];
} else {
if (last) {
if (last.length > 1) {
tokens.push(last.toLowerCase());
}
last = '';
}
}
}
if (last) {
if (last.length > 1) {
tokens.push(last.toLowerCase());
}
last = '';
}
return tokens;
}
When using Flexsearch, specify our own tokenizer() function:
const index = new Index({
encode: tokenizer
});
This implementation makes English, French, German, Russian, Chinese, Japanese, and Korean searchable.
Shortcomings
The above word segmentation algorithm is simple and straightforward, but it still has shortcomings:
- Chinese word segmentation is not implemented because we do not have a dictionary;
- Lexical conversion of English words is not implemented because there is no thesaurus;
- Both English and Chinese stop words are not implemented because there is still no vocabulary library.
However, considering that a feature-rich front-end search is implemented in just a few lines of code, the profit is really high, so let’s call it a day!